
Zum Einscannen von Dokumenten nutze ich einen MFP mit DADF unter Manjaro Linux mit GNOME Dokument-Scanner (simple scan).
Der Scanner lässt sich dabei bequem über das Netzwerk ansprechen und der automatischen Papiereinzug scannt Vorder- und Rückseite gleichzeitig in einem Durchzug. Das geht flott und ist bequem.
Die Schlichtheit des scan-Programms mit den wenigen Einstellungsmöglichkeiten empfinde ich dabei eher als Hilfe denn als Einschränkung.
Durch einen Artikel über Dokumentenmanagement und die wertvollen Kommentare der Nutzer wurde ich motiviert, endlich noch das i-Tüpfelchen drauf zu setzen und meine scans mittels OCR auch inhaltlich erfassbar zu machen.
Genauer gesagt, die Texterkennung so umzusetzen, dass über dem Bild ein zusätzlicher Layer mit dem erkannten Text eingefügt wird. Dies eröffnet zwei Möglichkeiten:
- Die Inhalte der Dokumente werden von den Werkzeugen des Betriebssystems indiziert und können gefunden werden. Ich muss mich also nicht mehr allein darauf verlassen, dass der Dateiname alles Wesentliche enthält inkl. den Begriff unter dem ich es später suche.
- Beim Lesen des PDF kann ich zielgenau Textstellen auswählen, kopieren, etc.
Wie sich herausstellte, erlaubt Dokument-Scanner das Einbinden eines Scripts für die Nachbearbeitung der scans (post-processing). Eine Option, die ich bisher nie beachtet habe, mir nun aber sehr gelegen kommt, da ich meinen workflow einfach erweitern kann und nichts grundlegend ändern muss.
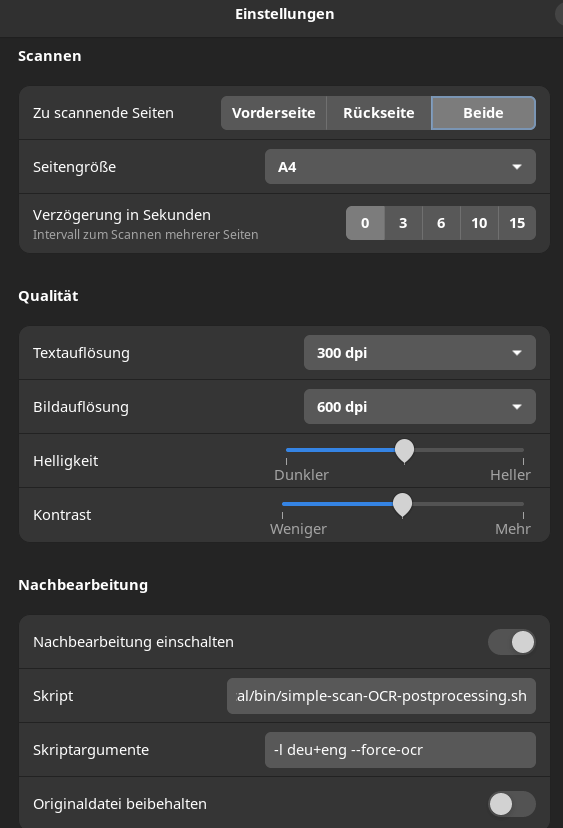
Dankenswerterweise gibt es auf der Projektseite im Ordner src ein Beispielscript (Permalink mit der Version zum Zeitpunkt der Erstellung dieses Artikels) mit dem sich das Ganze unter Zuhilfenahme von OCRmyPDF einfach umsetzen lässt.
Der vielleicht wichtigste Teil, der einem das Leben sehr erleichtert, ist in den Zeilen 30-33 und Zeile 61 zu finden. Der Rest ist nach kurzer Lektüre der OCRmyPDF-Doku auch so zu schaffen aber die Parameter liesen sich sonst nur umständlich ermitteln.
29| #Arguments
30| mime_type="$1"
31| keep_original="$2"
32| target="$3"
33| remainder="${@:4}"60| # Execute OCR
61| ${_ocrmypdf} ${remainder} - - <"$source" >"$target"
Hinweis: aus dem kompletten script ergibt sich darüberhinaus, dass source von $3 also target abgeleitet wird. Dies lässt sich besser verstehen, wenn man bedenkt dass target aus der Perspektive von Dokument Scanner betrachtet werden muss und nicht wie es in OCRmyPDF bzw. dem script Anwendung findet. Target ist schlicht der Dateiname unter dem Dokument Scanner den scan ablegen soll. Dass dieser Parameter zusätzlich im post-processing mit OCRmyPDF gebraucht wird, wo das einfachste Kommando ocrmypdf source.pdf target.pdf lautet, ist nachrangig aber nicht unwichtig.
Damit lässt sich nun das Beispielscript anpassen oder auch in vereinfachter Variante erstellen. Bsp:
#!/bin/bash
ocrmypdf -l deu+eng --force-ocr "$3" "$3"
Bei meinen Test hatte OCRmyPDF vorhandene mit Dokument Scanner erstellte PDF nicht verarbeiten wollen, da diese als tagged erkannt wurden. Ob dies auch beim post-processing zum Fehler geführt hätte oder nicht habe ich nicht getestet. Was ich einscanne hat sicher noch keinen Text und daher richtet dieses Argument keinen Schaden an.
Was habe ich bisher verschwiegen oder als bekannt vorausgesetzt?!
- OCRmyPDF hat gegenüber ähnlichen tools eine großen Vorteil. Es erzeugt PDF/A und die Textlayer liegen (meist) passend über dem Bild des Textes
- OCRmyPDF muss inkl. der Abhängigkeiten (python>=3.9′ ‚img2pdf‘ ‚python-pillow‘ ‚tesseract‘ ‚ghostscript‘ ‚unpaper‘ ‚pngquant‘ ‚python-pikepdf‘ ‚python-reportlab‘ ‚python-pdfminer‘ ‚python-tqdm‘ ‚python-pluggy‘ ‚python-rich‘ ‚python-importlib_resources‘ ‚python-packaging‘) installiert werden. Pamac hilft!
- Tesseract (die eigentliche Texterkennung) hat keine automatische Spracherkennung. Die Sprachpakete z.B. tesseract-data-deu und tesseract-data-eng (3-stelliger ISO Ländercode) müssen installiert sein und über das Argument
-langegeben werden, welche Sprachen im Dokument vorkommen. - Beim Speichern in Dokument Scanner muss PDF ausgewählt werden. Bei abweichenden Zielformaten muss post-processing abgeschaltet oder im script auf den mime_type getestet werden.
- Das script muss erstellt werden und ausführbar sein (chmod +x )
- Der Screenshot zeigt die Verwendung mit
${_ocrmypdf} ${remainder} - - <"$source" >"$target"im script. D.h. Argumente werden über die Dokument Scanner GUI übergeben.
Wir haben mit dem Thema Dokumentenmanagement gestartet und daher möchte ich zu guter Letzt noch auf eine Seite verweisen, deren Autor sich viele Gedanken zum Thema gemacht hat und ausführlich ein Datei- und Tag-basiertes System dafür vorstellt: Efficiently Managing Digital Files (e.g., Photographs) in Files and Folders